
2021-04-23 10:53
@张先生的jfinal DataSource是用来获取getConnection()的,至于内部是不是实现了连接池功能或是临时创建的Connection对象,这个是MyDataSource自己的事情。
看反馈内容:既然JF自带的DruidPlugin + Sqlite3Dialect不能连接,想自己创建Connection,那自然是自定义 DataSource了,可以先看看源码。
另外是不是可以先解密sqlite文件,再DruidPlugin + Sqlite3Dialect连接了?
我对sqlite操作不熟悉,不知道是不是有成熟的访问加密sqlite文件的工具了?
PS:附上一段伪代码:)
MyDataSource implements DataSource{
static {Class.forName("org.sqlite.JDBC");}
public Connection getConnection() throws SQLException {
return DriverManager.getConnection("jdbc:sqlite:test.db");
}
}
2021-04-22 18:55
自定义 DataSource就可以了
ActiveRecordPlugin arp = new ActiveRecordPlugin(new MyDataSource(...));
2021-04-22 11:14
@Moonights 纠正一下,HTTP请求也是后端的哦!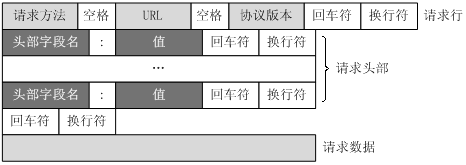
https://www.runoob.com/http/http-messages.html
2021-04-20 15:21
我们现有的方案是 复制JF的 Log4jLog,在中间复写自己的业务日志,代码里面都是全局位置Log log = Log.getLog(XXX.class)。
全局变量共享在拦截器configHandler配置的,里面也是通过ThreadLocal存放的。比如登录用户,请求路径target,参数,返回结果等等信息。
2021-04-19 10:54
巧了,我就喜欢分开用https://jfinal.com/share/1607
idea写java,HBuilderX写Enjoy模板。
他们都指向同一个文件夹就可以了。
idea的项目和模块源码输出路径直接指向:项目地址/WebRoot/WEB-INF/classes
如果用的是Tomcat开发,需配置部署根目录直接指向:项目地址/WebRoot
HBuilderX直接指向:项目地址/WebRoot
完美!
2021-04-18 13:09
MySQL那边有锁了吧,这个是业务操作问题,得看看业务代码的整体用法了。
如果不知道java这边哪个地方给加的锁,就从数据库那边追,https://www.cnblogs.com/guanbin-529/p/10993549.html
2021-04-14 13:54
我知道两个方案:
1:继承ActionHandler粘贴复制代码覆盖里面的 log.warn("404 Action Not Found: " https://jfinal.com/doc/2-7
2:如log4j.properties配置文件关闭WARN日志
2021-04-12 11:30
我有两个建议:
1:对第二个commonOrder增加一个s,commonOrders
2:使用 指令扩展 做一个#commonOrder 里面 extends Directive
exprArray.length 里面可以随意控制 https://jfinal.com/doc/6-4 》13、指令扩展
2021-04-10 20:42
自定义ActionHandler 了? 如果没有的话,需要处理一下,默认请求路径ActionHandler 不处理带 . 的资源,
if (target.indexOf('.') != -1) {
return ;
}
https://jfinal.com/doc/2-7
https://gitee.com/jfinal/jfinal/blob/master/src/main/java/com/jfinal/core/ActionHandler.java
2021-04-10 14:50
PS:构造器有:
RedisPlugin(String cacheName, String host)
RedisPlugin(String cacheName, String host, String password)
RedisPlugin(String cacheName, String host, int port)
RedisPlugin(String cacheName, String host, int port, String password)
RedisPlugin(String cacheName, String host, int port, int timeout)
RedisPlugin(String cacheName, String host, int port, int timeout, String password)
RedisPlugin(String cacheName, String host, int port, int timeout, String password, int database)
RedisPlugin(String cacheName, String host, int port, int timeout, String password, int database, String clientName)
2021-04-10 14:40
先把文档手册读上三遍以上再动手,https://jfinal.com/doc/6-7
JF的文档我全篇阅读应该有20+遍了。。。有朋友问我为啥对jf这熟悉了,因为我靠她吃饭,所以必须对她熟悉,文档读N遍,源码也读了N遍,代码细到函数知识点,画树图也手动画了N遍
2021-04-10 14:24
建议安装一个插件:“中文语言包” ,在插件市场中搜索:中文 ,就可以安装了。
安装中文环境后,就能看懂idea到底配置了什么功能。
再说上面描述的问题:
Not Found: / ,因为你把路由都注释掉了, 所以有访问时自然是报错误信息:“未找到:/” 了。
再说为啥启动后就会被访问一下,这个就得看你 idea自带的Tomcat是咋配置的了,估计是勾选了:启动后自动访问的功能。
再说为啥会访问两次,这个可能和浏览器有关系,有的浏览器打开网页后会自动请求favicon.ico文件,用于在浏览器上显示一个小图标,有的项目根目录里面刚好就没有这个文件,然后浏览器就会各种探测去请求,甚至有的浏览器会不断循环请求。
再说jfinal路由,这个Java里面应该没有比它更简洁高效的路由设计模式了,它就是一个HashMap通过请求地址键值Map来匹配,由ActionMapping管理,map.get不会随着用什么编写工具和其他平台而产生什么其他的规则。
敲码时感觉各种乱了或者做不出来的时候,注意先休息一下。出门走两圈呼吸清醒一下或者小眯一下。可能是用脑过度,思绪混乱了。静下来的时候再去细分析问题就会变得很简单









